
Machine learning relies on AI inference to make more accurate predictions based on analyzed sets of data. When an LLM produces outputs or makes fact-based decisions, it uses the patterns it recognizes from its training sessions to fine-tune its responses depending on the input and its context. AI-based tools do not know how exactly a trend will develop. However, they forecast its continuation based on historical data and the examples they analyze. In this guide, we’ll examine how LLMs predict the most probable next token based on stored knowledge and explore how this predictive capability supports coherent and context-aware output generation.
What is AI Inference?
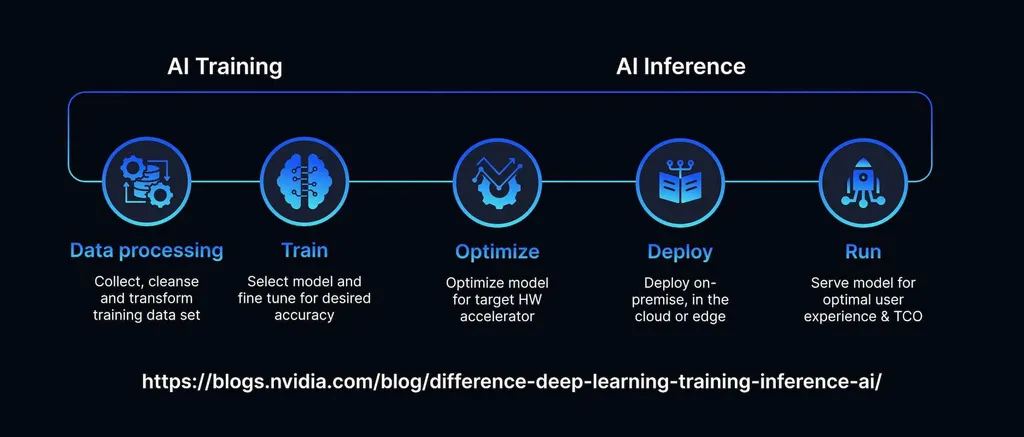
The term describes the functioning of AI models when they start producing results and use their capabilities to make predictions based on the insights they learned. AI apps and bots produce nearly instant replies. AI is used in spam-detection filters, autonomous vehicles fitted with navigation systems, and a variety of other modern products and services.
If you compare AI training vs inference, you will notice that both these consequential stages are necessary. When LLMs are trained on samples, their parameters are configured to streamline the process of making a decision. Social media already deploys algorithms that predict what content a user is likely to engage with based on the topics they were interested in before.
The main purpose of training is to achieve higher accuracy. The key objective of inference is to deploy a model to achieve top-level results in a particular situation. The same AI model may produce varying performance in different contexts.
Businesses should understand their workflows to deploy the AI in the most efficient way. Choosing the right inference approach helps them scale operations and reduce costs.
How to Use Inference in AI Systems
After gathering the necessary data, one should monitor the performance of AI apps closely to ensure the accuracy of execution. AI fine-tuning is all about improving output generation and using specialized datasets to solve a particular task. Companies should develop a resilient infrastructure to produce millions of predictions without delays.
During the AI serving stage, teams must deploy AI models for inference, configure API endpoints, and keep the system in an operational state. There are different kinds of AI environments one should be aware of when designing an efficient inference workload.
- On-premises. AI models utilize hardware owned and maintained by a company. This approach enables firms to control processes, decide where to store data, and allocate resources the way they see fit. The strategy is best suited to heavily regulated industries, where organizations must strictly adhere to privacy laws.
- Cloud. Web-based services allow organizations access to advanced AI software without making a substantial investment. However, while it’s the quickest way to scale, it results in higher data exposure.
- Edge deployment. It requires using computational resources located close to the data sources. Also known as an on-premise cloud model, it allows one to aggregate data from several devices or distribute it effectively. However, once local networks expand, it becomes challenging to handle updates across so many nodes.
- On-device. This type of deployment implies that AI inference is run on a user’s device, which allows one to maintain higher privacy. The computational capacity of a device may be quite limited. For instance, on a phone, it might be possible to apply some camera filters, convert voice to text, and perform other simple tasks using AI.
When looking for the best way to utilize AI, one should consider their workflows, clients’ needs, and the resources they have.
How Does AI Inference Work?
The process of producing an informative output relevant to a query involves preparing input data so that it can be processed by a model. It might be necessary to resize a submitted image or organize unstructured data first. For instance, computer vision models are specifically trained to extract data from media files to detect and classify objects.
Then, the AI analyzes the provided files or other inputs to discover patterns it can recognize. It could focus on particular shapes, hues, or textures it remembers after its training. Next, the model produces an output and sends it to the end user.
While the inference process may seem quick, it comprises multiple stages. When a system serves millions of customers and needs to provide replies in real time, it should use modern hardware to avoid latency.
AI Inference Use Cases
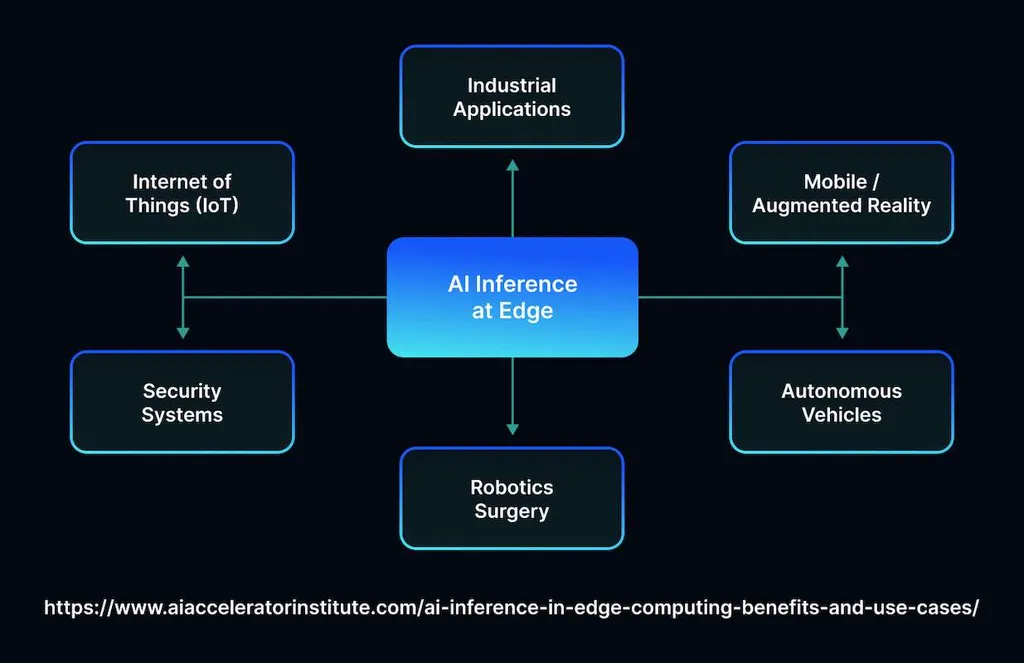
Enterprises rely on AI inference to automate their routines, make better decisions, and build powerful apps. Developers were quick to recognize the importance of algorithms for improving critical areas:
- Fraud detection. AI-powered systems analyze thousands of financial transactions, recognize the signs of suspicious user behavior, and monitor system logs to flag potentially illicit activities. Such efficient solutions facilitate taking proactive measures to prevent money laundering, security issues, and other problems. Once the model detects unauthorized transactions, it blocks them immediately.
- Recommendation engines. Clients expect personalized experiences and stay loyal to brands that tailor services depending on their needs. eCommerce platforms rely on inference, as it allows them to suggest relevant products to buyers. Similarly, streaming sites analyze viewers’ preferences and create a list of recommended movies based on the films they liked.
- AI agents. AI models can be taught to provide personalized assistance, answer queries at scale, and automate simple tasks. Customer support teams use them to simplify their workflows and let human agents focus on high-priority requests. Factories deploy AI to monitor quality and inspect assembly lines.
- Maintenance. The usage of predictive analytics facilitates processing sensor data from machinery and infrastructure to foresee performance issues and failures before they even occur.
Developers also use AI to build services designed to optimize routes, produce new content, summarize information, and create personalized ads.
Final Thoughts
AI inference capabilities are expected to become even more developed. Companies that invest in AI models and infrastructure will be able to achieve their performance goals and scale operations. However, building LLMs capable of handling enterprise-level issues is challenging and time-consuming. This is why many ventures entrust third-party providers with this task. MetaDialog develops advanced AI models and customizes them depending on customers’ preferences. Get in touch with the team and discover how to use AI inference to improve client experiences.